Building Index Files for Astrometry.net¶
Astrometry.net searches the sky using index files. These contain a set of “stars” (maybe also galaxies), selected so that they are relatively bright and cover the sky uniformly. They also contain a large number of features or quads that describe the local shape of sets of (usually four) stars. Each feature points back to the stars it is composed of. The Astrometry.net engine works by detecting stars in your image, and then looking at sets of (usually four) stars, computing their local shape, and searching in the index files for features with similar shapes. For each similar shape that is found, it retrieves other stars in the area and checks whether other reference stars are aligned with other stars in your image.
While we distribute index files based on the 2MASS and Tycho-2 astrometric catalogs that should work for most purposes, some people want to use other reference catalogs for their particular purpsose. This document explains how to build custom index files from a reference catalog.
- The steps are:
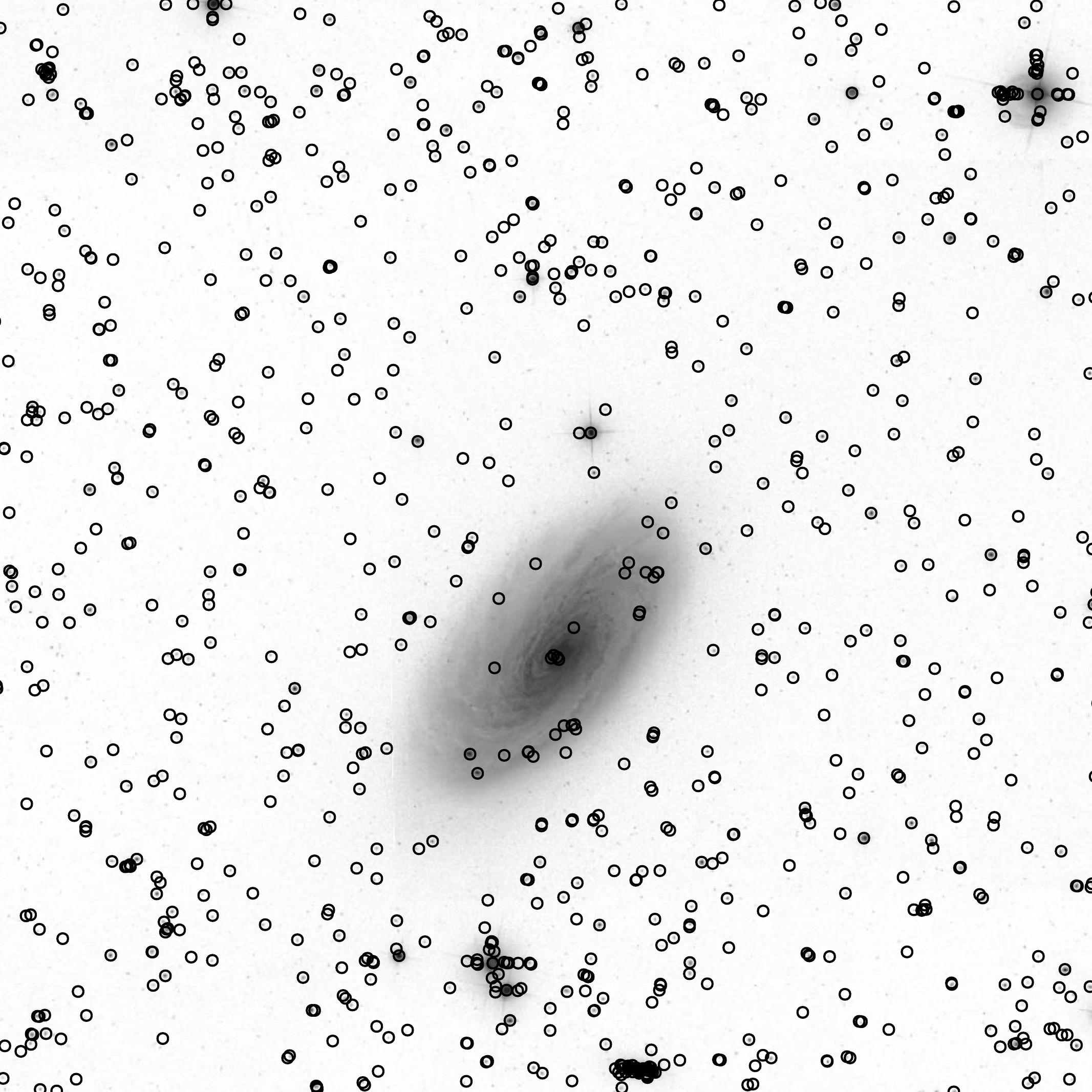
Here are some pictures of the index-building process itself:
A reference catalog: |
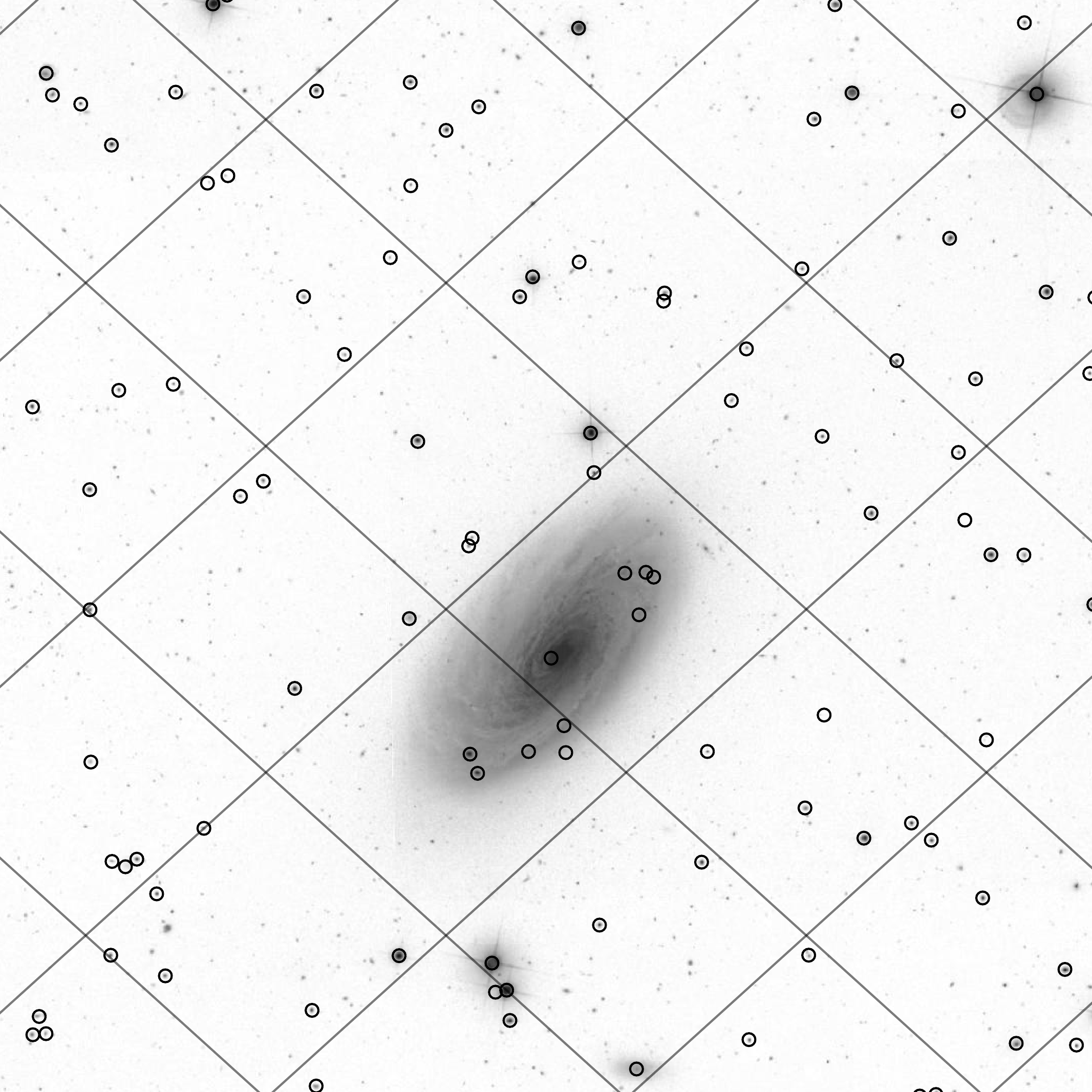
We lay down a healpix grid: |
And select the brightest stars in each cell: |
|

|
|
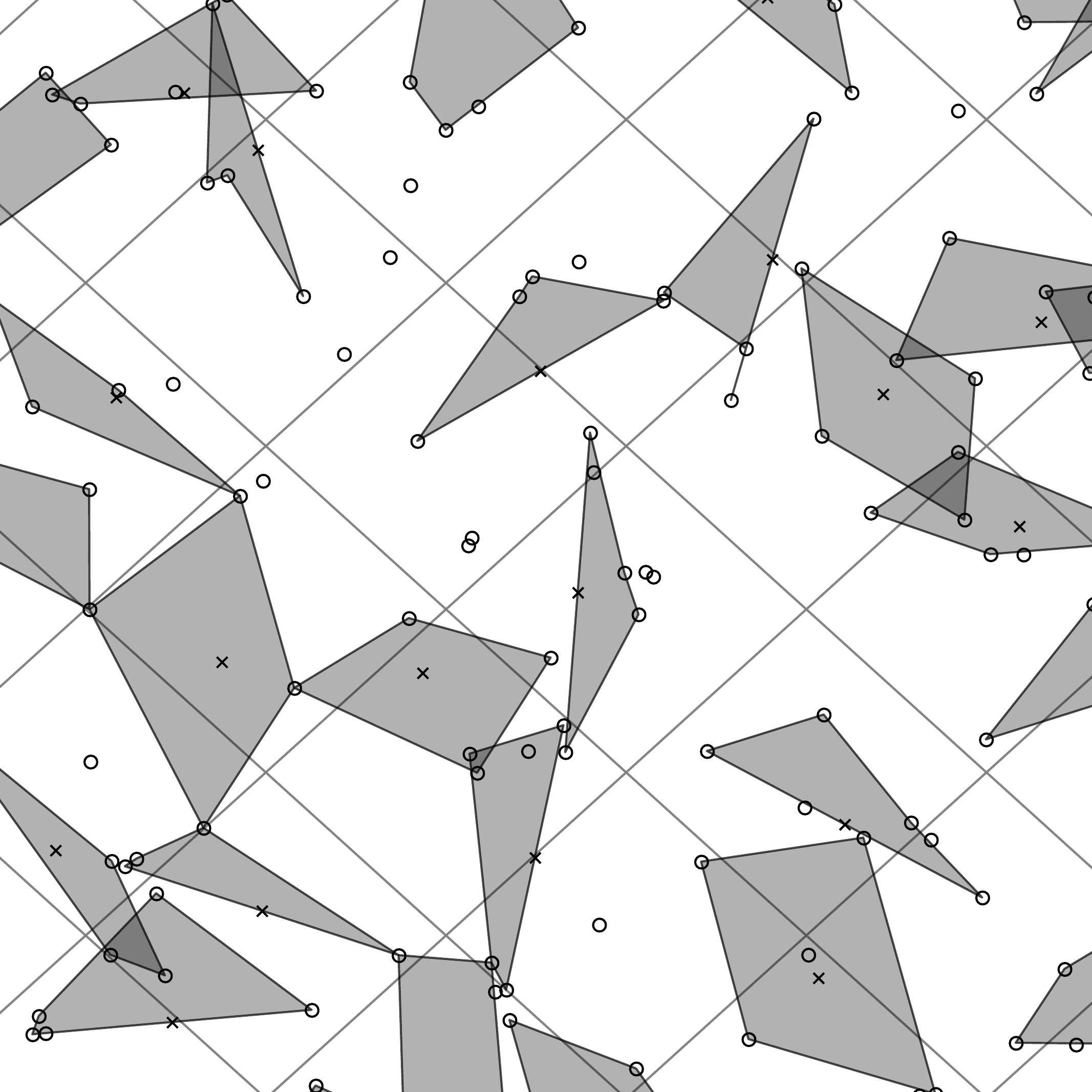
And then try to build a 4-star feature centered in each cell |
And again… |
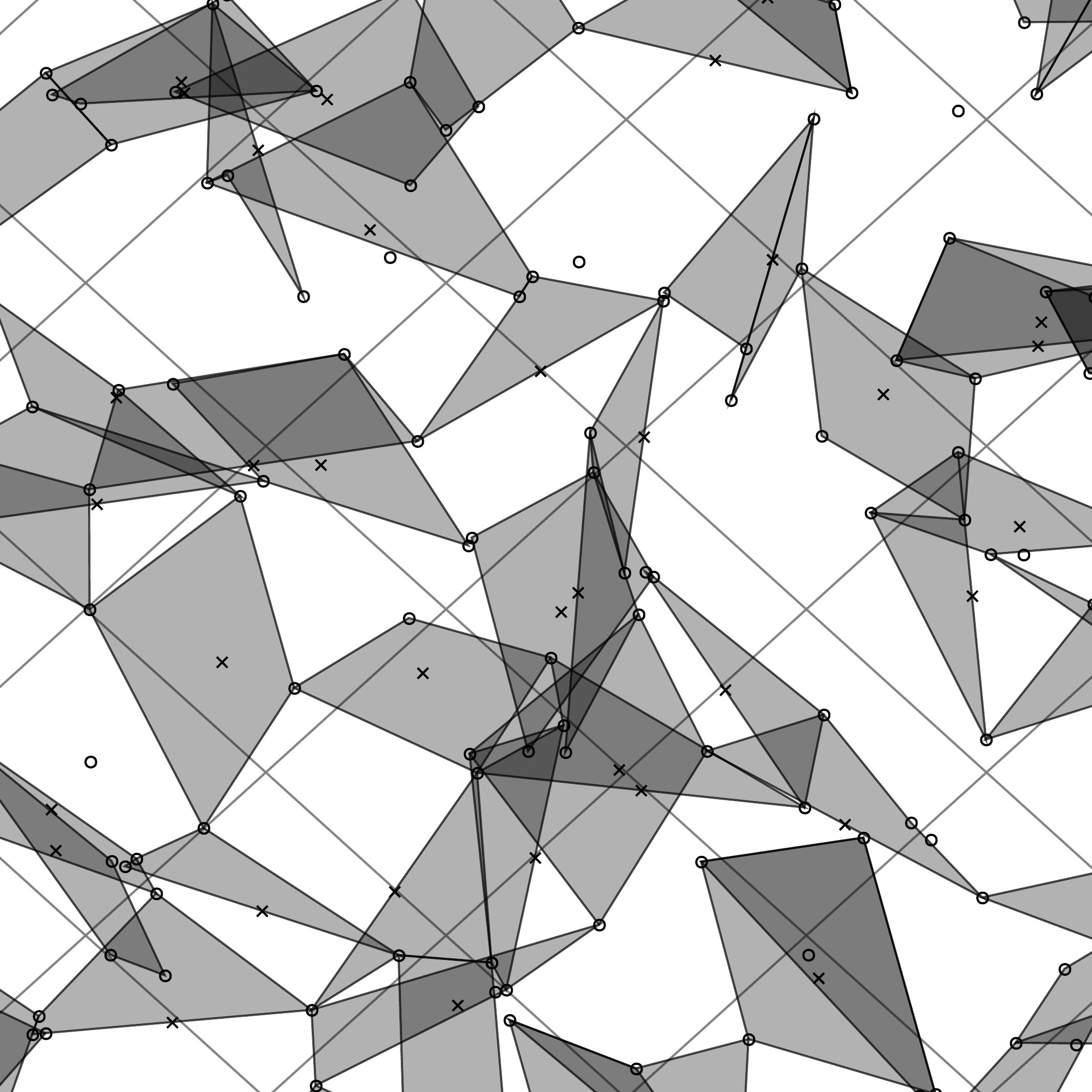
And again, until the sky is densely tiled in features. |
|
|

|
Convert your reference catalog to FITS tables¶
The Astrometry.net index files are FITS tables, and the index-building process take FITS tables as inputs.
Many astrometric reference catalogs are available in FITS format. For those that aren’t, here are a few options for converting to FITS BINTABLE (binary table) format: * text2fits.py in the Astrometry.net package—useful for CSV (comma-separated values) and other ASCII text inputs; this is a simple parser and takes a huge amount of memory to process big files. It would be possible to make it “stream” the inputs and outputs, but I haven’t done that (yet). * Custom format converters, including 2masstofits, nomadtofits, ucac3tofits, and usnobtofits (all in the Astrometry.net package). * Check the Vizier service to see if your catalog is available there; sometimes you can download it as FITS binary table (in the “Preferences” box for output format). I find the Vizier search engine impossible to use; just use your favorite web search engine to query, say, “vizier ucac4”. * Write your own custom converter. If I had to do this again, I would rewrite all the Xtofits converters above in python, probably using the struct module. But if you are converting a format that is very similar to one of the above, the fastest may be to copy-n-edit one of the existing ones. If you do this, please consider contributing your code back to the Astrometry.net codebase.
As for python FITS table handling, the best option is fitsio. The most popular option is probably pyfits. The Astrometry.net package includes a wrapper that can use either of those; util/fits.py.
The cfitsio package includes some tools for handling FITS tables, in particular liststruc (list the structure of a FITS file), listhead (print the headers), fitscopy (copy files, possible with manipulations; see extended filename syntax.).
Prepare your FITS tables¶
You may want to make some cuts, remove irrelevant columns, or otherwise prepare your FITS tables before feeding them into the index-building stage. At the very least, you want your FITS tables to contain RA and DEC columns, as well as a column that defines the brightness ordering of your stars: probably a MAG.
Any other columns you include can optionally be propagated into the index files, so that after getting an astrometric match you will also have access to this “tag-along” data. This is useful for, for example, doing an initial photometric calibration by tagging-along one or more bands of photometric data for each astrometric star.
As an example, the file 2mass-cut.py implements the cut we used to build our 2MASS-based index files. It removes any stars that are flagged in the 2MASS catalog (low quality, contaminated, etc), and writes out just the RA,Dec, and J-magnitude columns.
Split the sky into pieces¶
Optionally, you can split the sky into slightly overlapping pieces.
Why split the sky into pieces? First, it results in smaller files that can be easier to handle. Second, if you have an initial guess of where your image is on the sky, the Astrometry.net engine can avoid loading sky tiles that don’t overlap, so it results in faster and less memory-intensive searches.
If you don’t split the sky into pieces, at this point you should combine your input catalog files into a single FITS table, if you haven’t done that already. You can use the tabmerge program for that.
Splitting the sky into pieces is done using the hpsplit program. It takes a number of input FITS tables and produces one output table for each healpix tile:
> hpsplit -h
This program is part of the Astrometry.net suite.
For details, visit http://astrometry.net .
Subversion URL svn+ssh://astrometry.net/svn/trunk/src/astrometry/util/
Revision 22921, date 2013-06-02 15:07:59 -0400 (Sun, 02 Jun 2013).
Usage: hpsplit [options] <input-FITS-catalog> [...]
-o <output-filename-pattern> with %i printf-pattern
[-r <ra-column-name>]: name of RA in FITS table (default RA)
[-d <dec-column-name>]: name of DEC in FITS table (default DEC)
[-n <healpix Nside>]: default is 1
[-m <margin in deg>]: add a margin of this many degrees around the healpixes; default 0
[-g]: gzip'd inputs
[-c <name>]: copy given column name to the output files
[-t <temp-dir>]: use the given temp dir; default is /tmp
[-b <backref-file>]: save the filenumber->filename map in this file; enables writing backreferences too
[-v]: +verbose
The number of healpix tiles is determined by the Nside (-n) option.
-n 1 means split the sky into 12 pieces. -n 2 means split the sky
into 48 pieces. You probably don’t want to go any finer than that.
For reference, maps of the healpix tiles are here: Nside=1 healpixes; Nside=2 healpixes.
{kind=link}
{kind=link}
You probably want to set -m for the margin – extra overlapping
area around each healpix tile. You probably want to set this about
half as big as the images you are going to solve. This will mean that
in the margin areas, multiple healpix tiles will contain the same
stars.
If you want to “tag-along” extra information into the index files,
include those columns with the -c option.
Example hpsplit command:
hpsplit -o 2mass-hp%02i.fits -n 2 -m 1 2mass/2mass-*.fits
Notice the %02i in the output filename; that’s a “printf string”
that says, write an integer, using 2 digits, padding with zeros. The
outputs will be named 2mass-hp00.fits through 2mass-hp11.fits (for -n
1).
At the end of this, you will have 12 or 48 FITS tables (assuming your input catalog was all-sky; fewer if not). You will build several index file for each of these (each one covering one scale).
Building Index Files¶
Finally! The real deal.
build-astrometry-index has a daunting number of options, but don’t panic:
> build-astrometry-index
You must specify input & output filenames.
This program is part of the Astrometry.net suite.
For details, visit http://astrometry.net .
Subversion URL svn+ssh://astrometry.net/svn/trunk/src/astrometry/util/
Revision 22921, date 2013-06-02 15:07:59 -0400 (Sun, 02 Jun 2013).
Usage: build-astrometry-index
(
-i <input-FITS-catalog> input: source RA,DEC, etc
OR,
-1 <input-index> to share another index's stars
)
-o <output-index> output filename for index
(
-P <scale-number>: use 'preset' values for '-N', '-l', and '-u'
(the scale-number is the last two digits of the pre-cooked
index filename -- eg, index-205 is "-P 5".
-P 0 should be good for images about 6 arcmin in size
and it goes in steps of sqrt(2), so:
-P 2 should work for images about 12 arcmin across
-P 4 should work for images about 24 arcmin across
-P 6 should work for images about 1 degree across
-P 8 should work for images about 2 degree across
-P 10 should work for images about 4 degree across
etc... up to -P 19
OR,
-N <nside> healpix Nside for quad-building
-l <min-quad-size> minimum quad size (arcminutes)
-u <max-quad-size> maximum quad size (arcminutes)
)
[-S <column>]: sort column (default: assume the input file is already sorted)
[-f]: sort in descending order (eg, for FLUX); default ascending (eg, for MAG)
[-A <column>]: specify the RA column name in the input FITS table (default "RA")
[-D <column>]: specify the Dec column name in the input FITS table (default "Dec")
[-B <val>]: cut any object whose sort-column value is less than 'val'; for mags this is a bright limit
[-U]: healpix Nside for uniformization (default: same as -n)
[-H <big healpix>]; default is all-sky
[-s <big healpix Nside>]; default is 1
[-m <margin>]: add a margin of <margin> healpixels; default 0
[-n <sweeps>] (ie, number of stars per fine healpix grid cell); default 10
[-r <dedup-radius>]: deduplication radius in arcseconds; default no deduplication
[-j <jitter-arcsec>]: positional error of stars in the reference catalog (in arcsec; default 1)
[-d <dimquads>] number of stars in a "quad" (default 4).
[-p <passes>] number of rounds of quad-building (ie, # quads per healpix cell, default 16)
[-R <reuse-times>] number of times a star can be used (default: 8)
[-L <max-reuses>] make extra passes through the healpixes, increasing the "-r" reuse
limit each time, up to "max-reuses".
[-E]: scan through the catalog, checking which healpixes are occupied.
[-I <unique-id>] set the unique ID of this index
[-M]: in-memory (don't use temp files)
[-T]: don't delete temp files
[-t <temp-dir>]: use this temp directory (default: /tmp)
[-v]: add verbosity.
I will list them from most important to least (and roughly top-to-bottom).
Input file:
(
-i <input-FITS-catalog> input: source RA,DEC, etc
OR,
-1 <input-index> to share another index's stars
)
The -1 version is only used in the LSST index files; everyone else
should probably use -i. This will be the FITS file you have
carefully created as detailed above.
Output filename:
-o <output-index> output filename for index
Easy! I usually just name mine with a number, the healpix tile, and scale, but you can do anything that makes sense to you. These will be FITS tables, so the suffix .fits would be appropriate, but none of the code cares about the filenames, so do what you like.
Index scale:
(
-P <scale-number>: use 'preset' values for '-N', '-l', and '-u'
(the scale-number is the last two digits of the pre-cooked
index filename -- eg, index-205 is "-P 5".
-P 0 should be good for images about 6 arcmin in size
and it goes in steps of sqrt(2), so:
-P 2 should work for images about 12 arcmin across
-P 4 should work for images about 24 arcmin across
-P 6 should work for images about 1 degree across
-P 8 should work for images about 2 degree across
-P 10 should work for images about 4 degree across
etc... up to -P 19
OR,
-N <nside> healpix Nside for quad-building
-l <min-quad-size> minimum quad size (arcminutes)
-u <max-quad-size> maximum quad size (arcminutes)
)
...
[-U]: healpix Nside for uniformization (default: same as -n)
This determines the scale on which stars are selected uniformly on the sky, the scale at which features are selected, and the angular size of the features to create. In Astrometry.net land, we use a “preset” number of scales, each one covering a range of about square-root-of-2. Totally arbitrarily, the range 2.0-to-2.4 arcminutes is called scale zero. You want to have features that are maybe 25% to 75% of the size of your image, so you probably want to build a range of scales. For reference, for most of the experiments in my thesis I used scale 2 (4 to 5.6 arcmin features) to recognize Sloan Digital Sky Survey images, which are 13-by-9 arcminutes. Scales 3, 4, and 1 also yielded solutions when they were included.
You will run build-astrometry-index once for each scale.
Presets in the range -5 to 19 are available. The scales for the presets are listed in the Getting Index Files documentation.
Rather than use the -P option it is possible to specify separately
the different scales using -N, -l, -u, -U, but I wouldn’t
recommend it. The presets are listed in
build-index-main.chealpixeshttps://github.com/dstndstn/astrometry.net/blob/master/solver/build-index-main.c.
Sort column:
[-S <column>]: sort column (default: assume the input file is already sorted)
[-f]: sort in descending order (eg, for FLUX); default ascending (eg, for MAG)
[-B <val>]: cut any object whose sort-column value is less than 'val'; for mags this is a bright limit
Which column in your FITS table input should we use to determine which stars are bright? (We preferentially select bright stars to include in the index files.) Typically this will be something like:
build-astrometry-index -S J_mag [...]
By default, we assume that SMALL values of the sorting column are
bright – that is, it works for MAGs. If you have linear FLUX-like
units, then use the -f flag to reverse the sorting direction.
It is also possible to cut objects whose sort-column value is less
than a lower limit, using the -B flag.
Which part of the sky is this?:
[-H <big healpix>]; default is all-sky
[-s <big healpix Nside>]; default is 1
You need to tell build-astrometry-index which part of the sky it is indexing. By default, it assumes you are building an all-sky index.
If you have split your reference catalog into 12 pieces (healpix
Nside = 1) using hpsplit as described above, then you will run
build-astrometry-index once for each healpix tile FITS table and scale,
specifying the tile number with -H and the Nside with -s (default
is 1), and specifying the scale with -P:
# Healpix 0, scales 2-4
build-astrometry-index -i catalog-hp00.fits -H 0 -s 1 -P 2 -o myindex-02-00.fits [...]
build-astrometry-index -i catalog-hp00.fits -H 0 -s 1 -P 3 -o myindex-03-00.fits [...]
build-astrometry-index -i catalog-hp00.fits -H 0 -s 1 -P 4 -o myindex-04-00.fits [...]
# Healpix 1, scales 2-4
build-astrometry-index -i catalog-hp01.fits -H 1 -s 1 -P 2 -o myindex-02-01.fits [...]
build-astrometry-index -i catalog-hp01.fits -H 1 -s 1 -P 3 -o myindex-03-01.fits [...]
build-astrometry-index -i catalog-hp01.fits -H 1 -s 1 -P 4 -o myindex-04-01.fits [...]
...
# Healpix 11, scales 2-4
build-astrometry-index -i catalog-hp11.fits -H 1 -s 1 -P 2 -o myindex-02-11.fits [...]
build-astrometry-index -i catalog-hp11.fits -H 1 -s 1 -P 3 -o myindex-03-11.fits [...]
build-astrometry-index -i catalog-hp11.fits -H 1 -s 1 -P 4 -o myindex-04-11.fits [...]
You probably want to do that using a loop in your shell; for example, in bash:
for ((HP=0; HP<12; HP++)); do
for ((SCALE=2; SCALE<=4; SCALE++)); do
HH=$(printf %02i $HP)
SS=$(printf %02i $SCALE)
build-astrometry-index -i catalog-hp${HH}.fits -H $HP -s 1 -P $SCALE -o myindex-${HH}-${SS}.fits [...]
done
done
Sparse catalog?:
[-E]: scan through the catalog, checking which healpixes are occupied.
If your catalog only covers a small part of the sky, be sure to set
the -E flag, so that build-astrometry-index only tries to select features in
the part of the sky that your index covers.
Unique ID:
[-I <unique-id>] set the unique ID of this index
Select an identifier for your index files. I usually encode the date and scale: eg 2013-08-01, scale 2, becomes 13080102. Or I keep a running number, like the 4100-series and 4200-series files. The different healpixes at a scale do not need unique IDs.
Triangles?:
[-d <dimquads>] number of stars in a "quad" (default 4).
Normally we use four-star featurse. This allows you to build 3- or 5-star features instead. 3-star features are useful for wide-angle images. 5-star features are probably not useful for most purposes.
You probably don’t need to set any of the options below here¶
RA,Dec column names:
[-A <column>]: specify the RA column name in the input FITS table (default "RA")
[-D <column>]: specify the Dec column name in the input FITS table (default "Dec")
I would recommend naming your RA and Dec columns “RA” and “DEC”, but
if for some reason you don’t want to do that, you need to tell
build-astrometry-index what they’re called at this point, using the -A
and -D options:
build-astrometry-index -A Alpha_J2000 -D Delta_J2000 [...]
Indexing Details:
[-m <margin>]: add a margin of <margin> healpixels; default 0
Try to create features in a margin around each healpix tile. Not normally necessary: the healpix tiles can contain overlapping margins stars, so each one can recognize images that straddle its boundary. There’s no need to also cover the margin regions with (probably duplicate) features.
[-n <sweeps>] (ie, number of stars per fine healpix grid cell); default 10
We try to select a bright, uniform subset of stars from your reference
catalog by laying down a fine healpix grid and selecting -n stars
from each. This allows you to select fewer or more. With fewer, you
risk being unable to recognize some images. With more, file sizes
will be bigger.
[-r <dedup-radius>]: deduplication radius in arcseconds; default no deduplication
We can remove stars that are within a radius of exclusion of each other (eg, double stars, or problems with the reference catalog).
[-j <jitter-arcsec>]: positional error of stars in the reference catalog (in arcsec; default 1)
The index files contain a FITS header card saying what the typical astrometric error is. This is used when “verifying” a proposed match; I don’t think the system is very sensitive to this value.
[-p <passes>] number of rounds of quad-building (ie, # quads per healpix cell, default 16)
We try to build a uniform set of features by laying down a fine
healpix grid and trying to build a feature in each cell. We run
multiple passes of this, building a total of -p features in each
cell.
[-R <reuse-times>] number of times a star can be used (default: 8)
By default, any star can be used in at most 8 features. This prevents us from relying too heavily on any one star.
[-L <max-reuses>] make extra passes through the healpixes, increasing the "-r" reuse
limit each time, up to "max-reuses".
Sometimes the -R option means that we “use up” all the stars in an
area and can’t build as many features as we would like. This option
enables a second pass where we loosen up with -R value, trying to
build extra features.
Runtime details:
[-M]: in-memory (don't use temp files)
[-T]: don't delete temp files
[-t <temp-dir>]: use this temp directory (default: /tmp)
[-v]: add verbosity.
The help messages are all pretty self-explanatory, no?
Using your shiny new index files¶
In order to use your new index files, you need to create a backend config file that tells the astrometry engine where to find them.
The default backend config file is in /usr/local/astrometry/etc/backend.cfg
You can either edit that file, or create a new .cfg file. Either way, you need to add lines like:
# In which directories should we search for indices?
add_path /home/dstn/astrometry/data
# Load any indices found in the directories listed above.
autoindex
## Or... explicitly list the indices to load.
#index index-4200-00.fits
#index index-4200-01.fits
It is safe to include multiple sets of index files that cover the same region of sky, mix and match, or whatever. The astrometry engine will just use whatever you give it.
If you edited the default backend.cfg file, solve-field and
backend will start using your new index files right away. If you
create a new index file (I often put one in the directory containing
the index files themselves), you need to tell solve-field where it
is:
solve-field --backend-config /path/to/backend.cfg [...]
That’s it! Report successes, failures, frustrations, missing documentation, spelling errors, and such at the Astrometry.net google group.